大家好,我是小黑,一个在互联网苟且偷生的农民工。
在开始讲今天的内容之前,先问一个问题,使用int类型做加减操作是不是线程安全的呢?比如 i , i,i=i 1这样的操作在并发情况下是否会有问题?
我们通过运行代码来看一下。
public class AtomicDemo {
public static void main(String[] args) throws InterruptedException {
Data data = new Data();
Thread a = new Thread(() -> {
for (int i = 0; i < 100000; i ) {
System.out.println(Thread.currentThread().getName() "_" data.increment());
}
}, "A");
Thread b = new Thread(() -> {
for (int i = 0; i < 100000; i ) {
System.out.println(Thread.currentThread().getName() "_" data.increment());
}
}, "B");
a.start();
b.start();
// 等待A,B线程执行完毕
a.join();
b.join();
System.out.println(data.getI());
}
}
class Data {
private volatile int i = 0;
public int increment() {
i ;
return i;
}
public int getI() {
return i;
}
}
以上代码比较简单,通过A,B两个线程同时对Data对象中的i执行 操作,各自执行100000次,最后输出,如果说i 操作时线程安全的,那么最后输出的结果应该是200000,但是我们运行代码会看到如下结果:
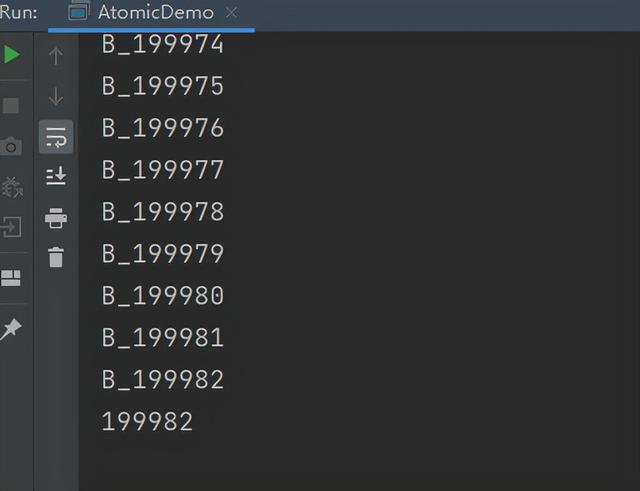
我们发现最后输出的并不是200000,而是199982,如果多执行几次的话,这个结果会发生变化,并且大多数情况下不会是200000。这主要是因为int类型的 操作不是原子的,i 同等于i=i 1,也就是加1这一步和对i重新赋值这一步不是同时完成的,不具备原子性,所以我们得出结论int类型的操作不是线程安全的。
在很多实际场景中都需要对一个数据进行并发操作,比如电商的秒杀活动中,对一个商品数量的扣减,那么我们想保证安全性应该怎么做呢?
首先我们可以想到的就是使用synchronized关键字对increment()这个方法加锁,这样就能保证每次只有一个线程能访问。
但是之前的文章中我们有讲到synchronized是一个重量级的悲观锁,我们的业务场景的并发可能是一段时间内的,多数情况下可能并不会有很多竞争,所以有没有更好的处理方式呢,答案就是通过AtomicInteger。
AtomicInteger

AtomicInteger是java.util.concurrent.atomic包中的一个类。我们看官方文档对于这个包的描述,说它是支持单个变量上的无锁线程安全编程的工具包,好像和我们期望的一样,在不加锁的情况下达到线程安全。
我们来修改一下上面例子的代码。
class Data {
private volatile AtomicInteger i = new AtomicInteger(0);
public int increment() {
return i.incrementAndGet();
}
public int getI() {
return i.get();
}
}
很简单,将原来的int修改为AtomicInteger,在执行increment()方法进行增加操作时,调用incrementAndGet()方法就可以了。同样我们运行代码,会发现,不管运行多少次,代码最后执行的结果都是一样的,200000。所以我们说AtomicInteger是线程安全的。除了incrementAndGet()方法以外,还有很多其他的操作,比如decrementAndGet(),getAndIncrement(),getAndDecrement(),getAndAdd(int delta),addAndGet(int delta)等等,实际上就是对i , i,i=i n,i =n这些操作的原子实现。
除了AtomicInteger以外,java.util.concurrent.atomic包中还有一些其他类型,比如Atomicboolean,AtomicLong等。
那么AtomicInteger是如何实现在不使用synchronized的情况下保证原子性的呢?我们来看一下源码。
public class AtomicInteger extends Number implements java.io.Serializable {
private static final Unsafe unsafe = Unsafe.getUnsafe();
// value在内存中的地址偏移值
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
// value为volatile的保证内存可见性
private volatile int value;
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) 1;
}
}
public final class Unsafe {
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
// 获取volatile的Int,保证拿到的值是最新的
var5 = this.getIntVolatile(var1, var2);
// compareAndSwapInt 比较并交换 native方法
} while(!this.compareAndSwapInt(var1, var2, var5, var5 var4));
return var5;
}
}
通过源码我们看到在incrementAndGet()方法中调用了Unsafe类的getAndAddInt方法,在这个方法内部对value进行compareAndSwapInt操作。通过这个方法名我们就可以看出是比较并交换,也就是我们之前提到过的CAS。也就是在执行赋值操作时,先看一下当前值是不是我加之前的值,如果不是,那我就重新加一次之后再进行比较,是一个循环的过程,这个过程也称作自旋。
CAS这种处理方式虽然很高效地解决了原子操作,但是它仍然存在三个问题,在实际开发中一定要注意,结合自己的实际业务场景使用。
ABA问题
什么是ABA问题呢,通俗理解,就是你大爷还是你大爷,你大妈已经不是你大妈了~
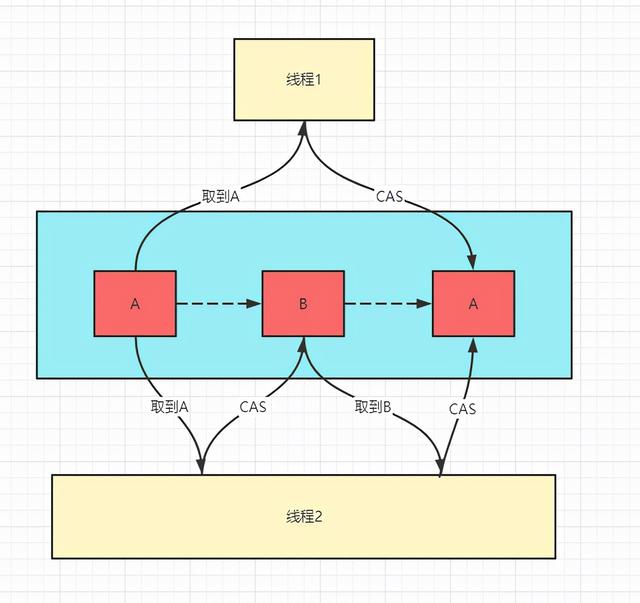
什么意思呢?就是当线程1取到A之后,有另一个线程2把A变成了B,又变成了A,当线程1再修改完值进行CAS比较时,发现值还是A,和自己取到的一样,就直接更新了,但是在这个过程中,这个A中间是发生过变化的。就好比一个小偷,偷了别人家钱然后再还回来,还是原来的钱吗?虽然你的钱没变,但是这个小偷已经触犯了法律,而你自己还不知道。
为了解决这个问题,atomic包中提供了一个类,我们看下是如何解决的。
public static void main(String[] args) throws InterruptedException {
AtomicStampedReference<String> ref = new AtomicStampedReference<>("A", 0);
new Thread(() -> {
try {
int stamp = ref.getStamp();
String reference = ref.getReference();
System.out.println("线程1拿到的值:" reference " stamp:" stamp);
// sleep 2秒模拟线程切换到2
TimeUnit.SECONDS.sleep(2);
boolean success = ref.compareAndSet(reference, "C", stamp, stamp 1);
System.out.println(Thread.currentThread().getName() " " success);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "线程1").start();
new Thread(() -> {
// 先改为B
int stamp = ref.getStamp();
String reference = ref.getReference();
System.out.println("线程2拿到的值:" reference " stamp:" stamp);
ref.compareAndSet(reference, "B", stamp, stamp 1);
// 再改回A
stamp = ref.getStamp();
reference = ref.getReference();
System.out.println("线程2拿到的值:" reference " stamp:" stamp);
ref.compareAndSet(reference, "A", ref.getStamp(), stamp 1);
}, "线程2").start();
}
我们可以看到AtomicStampedReference的compareAndSet()方法有4个参数:
- expectedReference:表示期望的引用值
- newReference:表示要修改后的新引用值
- expectedStamp:表示期望的戳(版本号)
- newStamp:表示修改后新的戳(版本号)
什么意思呢?就是在修改时不光比较值是不是和获取到的一样,还要比较版本号。这样的话,每次操作时都对版本号加1,那么就算值从A改为B再改回A,但是版本号从0改成了1又改成了2,并没有变回0,就可以避免ABA问题的发生。
循环时间变长
在并发非常大的情况下,使用CAS可能会存在一些线程一直循环修改不成功,导致循环时间变长,会给CPU带来很大的执行开销。并且由于AtomicReference中的引用是volatile的,为了保证内存可见性,需要保证缓存一致性,通过总线传输数据,当有大量的CAS循环时,会产生总线风暴。
只能保证一个变量的原子操作
CAS的第三个问题就是AtomicReference中只能存放一个变量,如果需要保证多个变量操作的原子性,是做不到的。对于这种情况只能使用synchronized或者juc包中的Lock工具。
小结简单做个小结,使用int类型在并发场景下存在线程安全问题,可以用AtomicInteger来保证原子性操作,Atomic是通过CAS做到无锁线程安全的。但是CAS有三个问题,第一ABA问题,可以通过AtomicStampedReference解决;第二竞争激烈情况下循环时间会变长,会产生总线风暴;第三只能保证一个变量的原子操作。
具体业务场景中是使用synchronized,Lock等锁工具还是使用Atomic的CAS无锁操作,还是要结合场景考虑。
好的,今天的内容就到这里,我们下期见。
,




