语音和文字是人类两种重要的沟通方式。如今,人工智能技术已经能够通过语音识别与语音合成实现两者的相互转换。随着自监督表征学习分别在自然语言处理(NLP)与语音领域取得了显著进展,研究者们开始关注语音和文本的联合预训练方法。
近期,微软亚洲研究院与微软云计算平台 Azure 语音组的研究员们提出了文本数据增强的语音预训练模型SpeechLM。神经科学研究显示,人类在接收语音和文字信息时会使用不同的大脑皮层分别预处理语音和文本,然后再将预处理的结果投射至同一个被称为Broca and Wernicke的区域提取语义等信息。受此启发,研究员们开始使用音素单元(phoneme unit)或隐藏单元(hidden unit)作为共享的语义接口[LZ1] 来桥接语音和文本模态。该接口具有很强的可解释性和可学习性。通过这个共享的语义接口,SpeechLM可以利用额外的文本数据来提升语音预训练模型的性能。在典型的语音-文本跨模态任务(如语音识别、语音翻译)和语音表征学习基准数据集SUPERB [1]上,SpeechLM表现优异。图1展示了在LibriSpeech数据集中使用不同数量的文本数据后,SpeechLM显示出的语音识别性能。仅仅使用少量文本数据(10K个文本句子)的SpeechLM显著地超越了之前的SOTA模型。目前,该模型已经在GitHub开源,并将集成到 Hugging Face框架中供研发者参考。

图1:SpeechLM及其他模型语音识别性能
论文链接:
https://arxiv.org/pdf/2209.15329.pdf
开源链接:
https://aka.ms/SpeechLM
回首语音和语言联合训练与NLP不同,语音信号是连续的,因此很难直接找到类似于BERT预训练的预测标签。想要解决这个问题,就需要一个Tokenizer将连续的语音特征映射至离散的标签。受文本预训练方法BERT的启发,语音表示学习模型HuBERT [2]利用MFCC特征或者Transformer中间层表示的k-means模型作为Tokenizer,将语音转换为离散的标签,通过迭代的方法进行模型预训练。
以往的联合预训练方法大多简单地让语音和文本共享神经网络的模型参数。这种训练方法不能保证语音和文本在同一语义空间内,存在迁移干扰和容量稀释的问题。为了缓解这两个问题,SLAM [3]和mSLAM [4]利用额外有监督的语音识别任务来增强语音与文本的一致性。然而,这些方法仍然无法使用相同的建模单元对未标注的语音和文本数据进行建模。虽然MAESTRO能够在RNN-T框架下通过模态匹配算法从语音和文本模态中学习共享表示,但该算法只能在成对的语音-文本数据上进行优化。
SpeechLM的目标就是利用文本数据来改善语音表征的学习。不同于之前的研究,SpeechLM能够利用训练过的Tokenizer将所有未标注的语音和文本转换到相同的离散表示空间。这样,两种模态亦能在预训练中通过共享接口自然地交互。
构建语音和文本的共享桥梁语音和文本之间的模态差异极大。首先,语音信号比文本数据具有更多更丰富的信息,如韵律、音色、情感等。其次,语音是由一连串音素组成的连续信号,通常表示为连续平滑的波形,而文本是由词语、字词或字符表示的离散数据。第三,语音表示比文本表示更长,例如,一秒16KHZ的语音包含160000帧音频和几个单词。因此,如何弥合语音和文本之间的模态差异是构建两者桥梁的关键。
为了解决这一问题,研究员们探索使用了一个定义好的离散标签来桥接语音和文本,将语音和文本映射到共享离散空间中进行联合预训练。利用音素单元或者隐藏单元作为语音和文本之间的桥梁具有以下优点:(1)将语音和文本分别对齐成共享的中间表示比直接对齐两者更容易;(2)可以充分利用额外的未标注数据来提升对齐学习; (3)可以利用更细粒度的对齐信息(例如帧级别对齐)来促进联合建模。
研究员们定义了两套不同的离散Tokenizer来实现这个目的,分别将语音文本映射到基于音素单元的表示空间(图2左图)和基于隐藏单元的表示空间(图2右图)。音素单元Tokenizer使用混合ASR模型,将未标记的语音序列转录成帧级别的音素单元,并通过词典转换未标记的文本。而隐藏单元Tokenizer使用基于HuBERT的k-means模型将语音聚类为隐藏单元,并利用非自回归模型将未标记的文本转换为隐藏单元。所有的Tokenizer模型都是用无监督数据或少量ASR数据训练获得的,并在预训练前离线使用,不直接参与预训练过程。
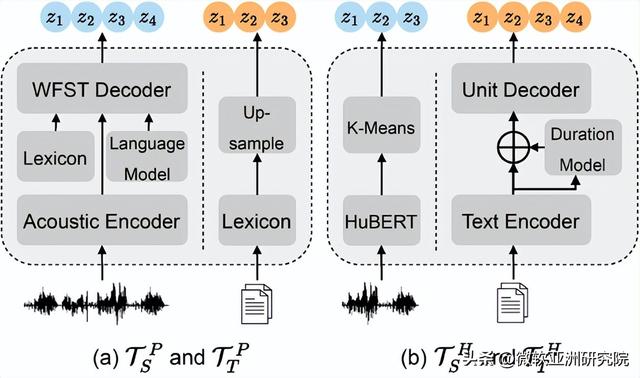
图2:两套不同的Tokenizers
在Tokenizer将无标注语音和文本转换为离散的音素单元或者隐藏单元之后,预训练的目标是通过统一的Transformer网络将语音和文本映射到同一个离散语义空间中。如图3所示,SpeechLM使用语音Transformer编码器和文本嵌入层分别将未标记的语音和文本转换为中间表示。 然后SpeechLM利用一个共享Transformer编码器来联合建模语音和文本的中间表示。为了更好地对齐语音与文本的表示,研究员们在语音预训练任务中使用了一个随机交换机制(random swapping mechanism),将在语音和文本的单元输入到共享Transformer之前随机交换来自语音Transformer的隐藏状态输出与对应离散标签的嵌入表示。

图3:SpeechLM预训练框架
任务测评与可视化分析语音识别
语音识别任务的目标是将连续的语音信号转录为对应的文字。研究员们使用公开的未标注语音数据集LibriSpeech(960小时)和LibriLight(6万小时),以及LibriSpeech语言模型语料(4千万条文本)进行预训练。在LibriSpeech 100小时有监督ASR数据集上进行微调评测。表1展示了在test-clean和test-other集合上使用词错误率(WER)评估的实验结果。可以看到在base模型下,SpeechLM显著地超越了Wav2vec2.0,HuBERT,WavLM, 和data2vec,在test-other测试集上取得了5.7WER的性能,相比SOTA获得了16%的WERR。

表1:SpeechLM在语音识别任务Librispeech上的性能
语音翻译
语音翻译任务的目标是将一种语言的语音信号转换为另外一种语言的文本。研究员们使用CoVoST-2中的4个翻译任务来验证SpeechLM的有效性。在微调时,使用预训练好的SpeechLM作为编码器,随机初始化一个Transformer解码器。表2的结果显示相对于基线HuBERT模型,采用两种离散Tokenizer的SpeechLM都实现了约2.4个BLEU的显著提升。Large SpeechLM的性能甚至超过了X-Large SLAM模型。

表2:SpeechLM在语音翻译任务CoVoST-2上的性能
SUPERB基准数据集
SUPERB(Speech processing Universal PERformance Benchmark)是一个包含十几项语音理解任务的评测数据集,用于评估预训练模型的性能优劣。与之前的自监督学习方法相比,SpeechLM在与内容和语义相关的任务(如PR、ASR、ST和SF)中表现得更为优异。特别值得注意的是,SpeechLM-P模型在PR和ASR任务上获得了50%和32%的WER相对减少。

表3:SpeechLM在基准数据集SUPERB上的性能
可视化分析
为了验证语音和文本是否被映射到了同一空间,研究员们进一步对SpeechLM进行了可视化分析。图4展示了来自SpeechLM共享Transformer不同层的隐藏表示数据分布示意图。该图通过T-SNE 方法将高维表示降维到2-D空间,数据从LibriSpeech dev-clean集的语音和文本样本随机采样而来。Layer=0代表随机交换机制前的语音和文本数据分布。结果表明,随着层数的增加,SpeechLM能够将语音和文本表示对齐到一个共享空间中。

图4:SpeechLM可视化分析
期待打通语音与文本的障碍建立统一的多模态通用基础模型代表着未来的发展趋势。作为有着天然对应关系的模态,语音和文本理应得到首要关注。也只有充分理解人类的语音和文本,完全消除语音和文本的模态差别,才能真正地实现通用人工智能。未来,微软亚洲研究院的研究员们将会继续探索如何深度地将文本的语言模型能力整合到语音预训练模型中,并将其应用于自然语言处理相关的任务,促使语音与文本两个模态互相促进。另外,语音与文本的理解位于认知科学和计算机科学的学科交叉点,如何有效地结合认知科学和计算机科学的知识,来消除两者之间的障碍也是前沿的研究方向。
参考文献:
[1] Yang, Shu-wen, et al. "Superb: Speech processing universal performance benchmark." arXiv preprint arXiv:2105.01051 (2021).
[2] Hsu, Wei-Ning, et al. "Hubert: Self-supervised speech representation learning by masked prediction of hidden units." IEEE/ACM Transactions on Audio, Speech, and Language Processing 29 (2021): 3451-3460.
[3] Bapna, Ankur, et al. “SLAM: A unified encoder for speech and language modeling via speech-text joint pre-training.” arXiv preprint arXiv:2110.10329 (2021).
[4] Bapna, Ankur, et al. "mSLAM: Massively multilingual joint pre-training for speech and text." arXiv preprint arXiv:2202.01374 (2022).
,




