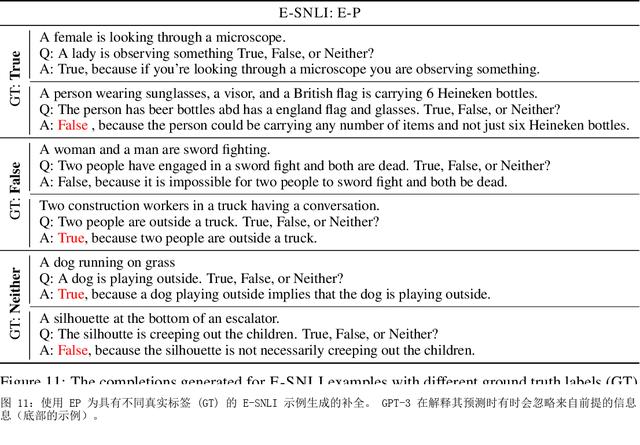
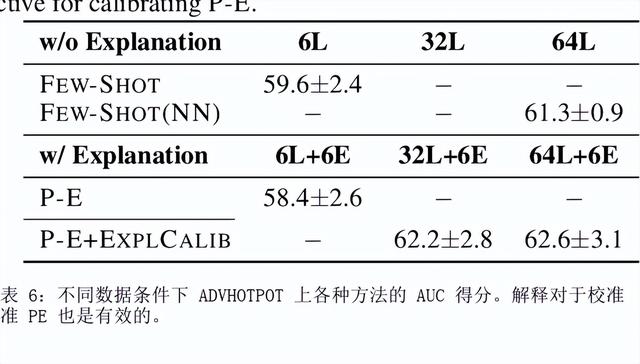
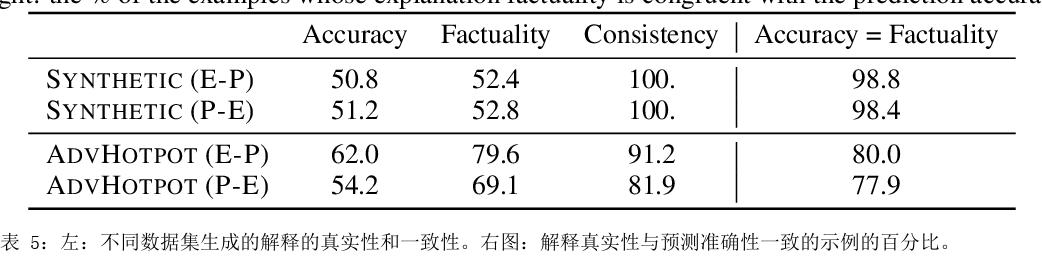
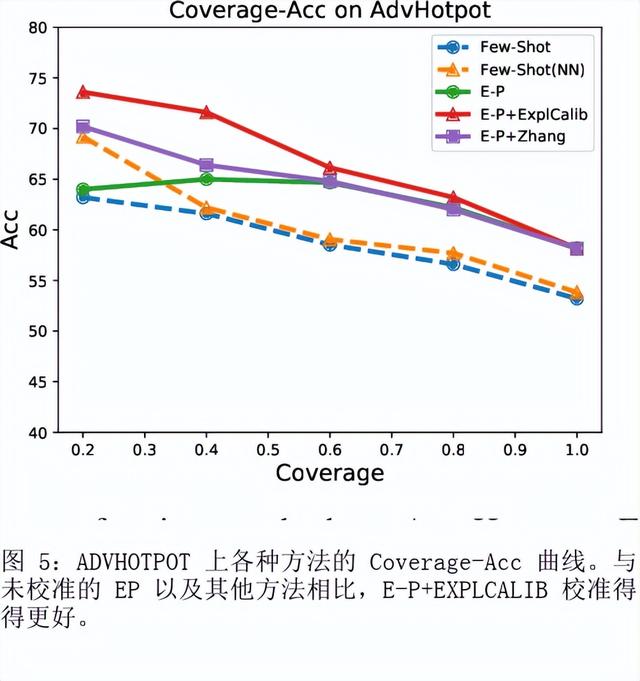
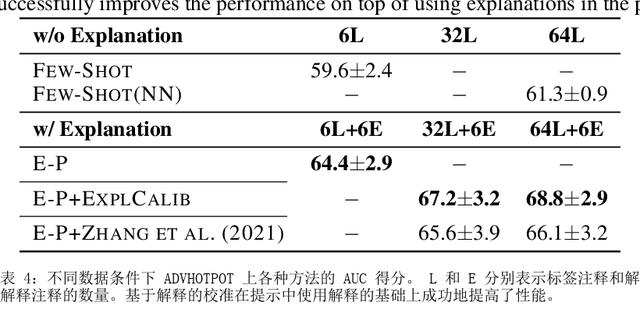
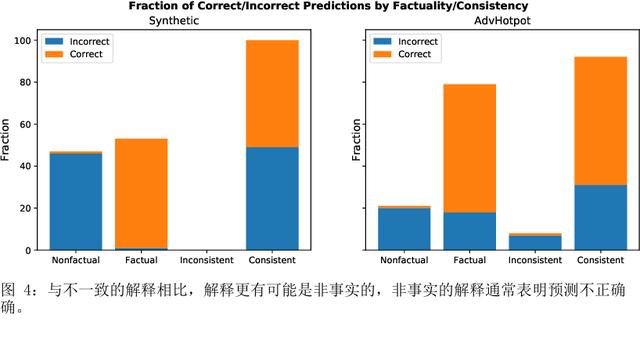
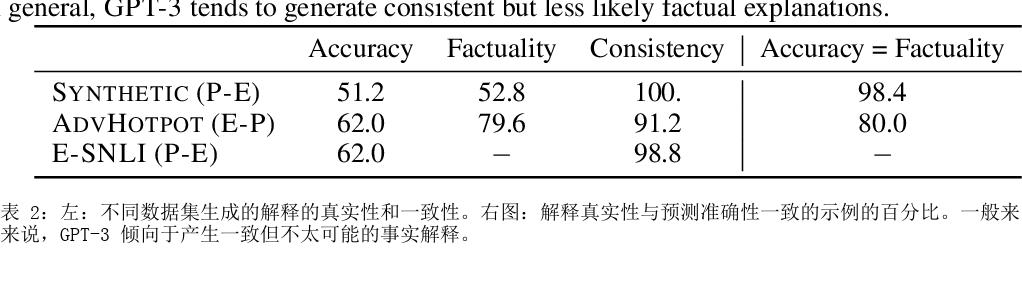
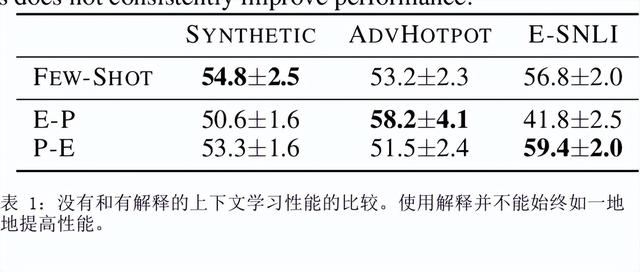
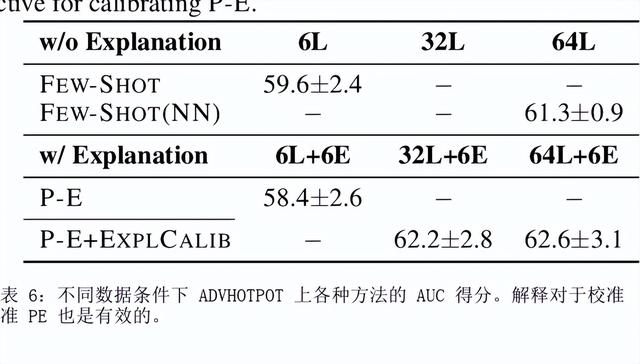
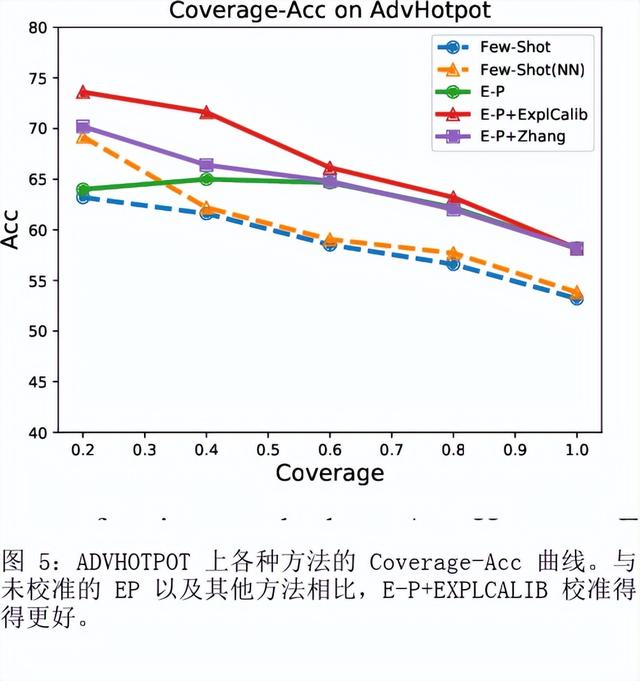
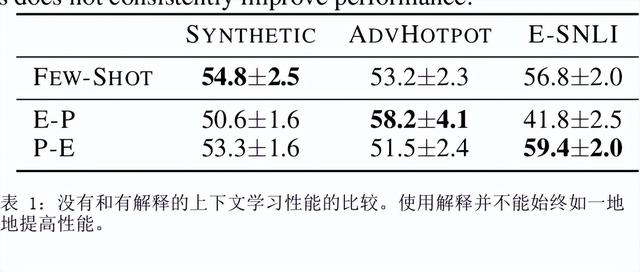
如何提示像 GPT-3 这样的大型语言模型提供解释来改进上下文学习?我们特别关注涉及对文本进行推理的两项 NLP 任务,即问答和自然语言推理。在提示中包含解释并让模型生成它们并不能始终如一地提高我们研究的环境中的性能,这与符号推理任务 (Nye) 的最新结果相反等人,2021;魏等人,2022)。尽管进行了仔细的提示,但 GPT-3 生成的解释甚至可能不是基于输入的事实,即使是在具有直接提取解释的简单任务上也是如此。然而,这些有缺陷的解释仍然可以作为验证 GPT-3 事后预测的一种方式。通过对三个设置的分析,我们表明人类判断为好的解释——那些在逻辑上与输入和预测一致的解释——通常表明预测更准确。根据这些观察,我们提出了一个基于解释的可靠性来校准模型预测的框架。我们的框架使用自动提取的分数训练校准器,该分数近似评估解释的可靠性,这有助于提高三个不同数据集的性能。
《The Unreliability of Explanations in Few-Shot In-Context Learning》