词向量
词向量是我们提高分析单词、句子和文档分析关系的能力方面的重大飞跃。在这样做的过程中,他们通过为机器提供更多关于单词的信息,而不是以前使用传统的单词表达方式实现的技术,来提高技术。它是使语音识别和机器翻译等技术成为可能的词向量。其实对于单词向量有很多很好的解释,但是在这一篇中,我想让这个概念能够被数据和研究人员所使用,因为可能他们对于自然语言处理方面不太熟悉。
什么是词向量?
词向量只是代表单词意义的数字向量。就目前而言,这还不是很清楚,但我们一会儿会回头稍微回顾一下。首先,要考虑为什么词向量被认为是从传统的词汇表达中跳跃而来的。
对于一些机器学习(ML)有用的NLP的传统方法,例如独热编码和词袋模型(即,使用虚拟变量来表示观察中的词的存在或不存在,即句子)任务,不捕获关于单词意义或上下文的信息。这意味着潜在的关系,如情境亲密关系,并不是通过一系列的词汇来获取的。例如,独热编码不能捕捉简单的关系,例如确定“狗”和“猫”这两个词通常是指在家庭中经常被讨论的宠物。
在该图中,我们想象每个维度都具有明确定义的含义。例如,如果您想象第一个维度代表“动物”的含义或概念,那么每个单词在该维度上的权重代表它与该概念的紧密联系。
这是对单词向量的相当大的简化,因为这些维度并不具有如此明确定义的含义,但它是围绕单词向量维度概念的最有用的直观方式。
我们创建一个单词列表,应用spaCy的解析器,为每个单词提取矢量,将它们堆叠在一起,然后提取两个主要的主件进行可视化。

在这里,我们简单地为不同的动物和可能用于描述其中一些的单词提取矢量。正如开头提到的那样,单词向量非常强大,因为它们允许我们(和机器)通过将它们表示为连续的向量空间来识别不同单词之间的相似性。你可以在这里看到“狮子”、“老虎”、“猎豹”和“大象”这些动物的如何非常接近。这很可能是因为他们经常在类似的背景下讨论。例如,这些动物是体格较大、野生,并且可能是危险的。事实上,描述性词语“野生”与这组动物非常接近。
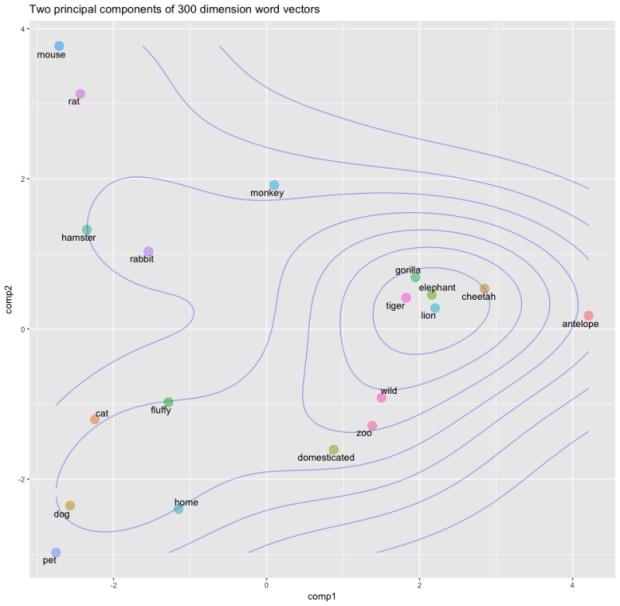
类似的词在矢量空间中映射在一起。注意“猫”和“狗”有多接近“宠物”,“大象”,“狮子”和“老虎”是如何聚集在一起的,以及描述性词汇是如何聚集在一起的。
这里有趣的是,“野生”、“动物园”和“驯化”这两个词又是如何紧密地相互映射。这是有道理的,因为它们是经常用来描述动物的词,但突出了词向量的惊人力量!
词向量从哪里来?
在这一点上一个很好的问题是,这些尺寸和重量来自哪里?有两种常用的方法来生成词向量:
1.字数/上下文的共生
2.给定词的上下文预测(skip-gram神经网络模型,即word2vec)
注意:下面我描述一个高级的word2vec模型来生成单词向量,但是可以在这里找到一个很好的计数/共生方法的概述。
两种产生单词向量的方法建立在弗斯(Firth)(1957)的分布假说上,它指出:
“你应该知道它保存的公司的一个词。”
换言之,具有相似背景的词语往往具有相似的含义。实际意义上的单词的背景是指其周围的单词和单词矢量(典型地)是通过预测给定单词的背景的概率来生成的。换言之,构成单词向量的权重是通过预测其他单词上下文接近给定单词的概率来学习的。这类似于试图填补某些给定输入词的空白。例如,考虑到输入序列,“毛茸茸的狗在追逐猫时吠叫”,“狗”和“吠叫”这两个词的前后两个词(前后两个词)会看起来像:

我不想深入研究神经网络如何学习单词嵌入的数学细节,因为更有资格这样做的人已经解释了这一点。特别是,这些帖子在尝试了解如何学习单词向量时对我很有帮助:
1.深度学习、NLP和陈述http://colah.github.io/posts/2014-07-NLP-RNNs-Representations/
2.词向量的惊人力量https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
3.Word2Vec教程:Skip-Gram模型http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
但是,鉴于其广受欢迎和有用性,可以触及word2vec模型的工作。 word2vec模型仅仅是一个带有单个隐藏层的神经网络,其被设计为通过估计单词与另一个作为输入给出的单词“接近”的概率来重构单词的上下文。
该模型接受语料库中每个词的单词,进行上下文配对训练,即:
(DOG,THE)(DOG),FLUFFY(DOG,BARKED)(DOG,AS)
请注意,这在技术上是一个监督式学习过程,但您不需要标注数据。标签(目标/因变量)是从构成焦点词上下文的词中生成的。因此,使用窗函数模型会学习使用单词的上下文。在这个简单的例子中,模型将会学到“毛茸茸”和“吠叫”会被用在单词“狗”的上下文中(由窗口长度定义)。
有关word2vec模型创建的单词向量的迷人之处之一是它们是预测性任务的副作用,而不是其输出。换句话说,不预测单词向量(它是预测的上下文概率),单词向量是用于预测任务的输入的学习表示——即预测给定上下文的单词。向量这个词是模型试图学习单词的一个很好的数字表示,以便最小化其预测的损失(错误)。
随着模型的迭代,它会调整其神经元的权重,以尽量减少其预测的误差,并在此过程中逐渐改进其单词表示。在这样做的时候,这个词的“含义”会嵌入到网络隐藏层中每个神经元所学习的权重中。
因此,word2vec模型接受作为输入的单个词(表示为文集中所有词中的单热编码),并且该模型试图预测在语料库中随机选择的词在附近位置处的概率输入词。这意味着对于每个输入词有n个输出概率,其中n等于语料库的总大小。这里的神奇之处在于,训练过程仅包含单词的上下文,而不包含语料库中的所有单词。
这意味着在上面我们的简单例子中,给定单词“狗”作为输入,“吠叫”将比“猫”具有更高的概率估计,因为它在上下文中更接近,即在训练过程中学习。换句话说,该模型试图预测语料库中的其他词属于输入词的上下文的概率。因此,考虑到上面的句子(“毛茸茸的狗冲它追逐的一只猫吠叫”)作为输入模型的运行看起来像这样:

经历这个过程的价值是提取模型隐藏层神经元学习到的权重。正是这些权重形成单词向量,即如果您有一个300维的神经元隐藏层,则将为语料库中的每个单词创建一个300维的单词向量。因此,这个过程的输出是大小为n的输入词* n隐藏层神经元的单词——矢量映射。
下一步
词向量是一个非常强大的概念和一项技术,可以在NLP应用程序和研究中实现重大突破。它们还突出了神经网络深度学习的美妙之处,特别是隐藏层中输入数据的学习表示的力量。
,




