作者 | 蒋宝尚、赛文、青暮
编辑 | 青暮
还记得《生活大爆炸》里谢耳朵完虐舍友伦纳德时玩的三维国际象棋吗?


三维国际象棋或者空间国际象棋指任何一种在空间中(也就是不局限于一个平面棋盘)的棋类游戏。从20世纪早期就有这种象棋形式,最早的版本之一是“德国式空间国际象棋”,并在《星际迷航》系列中频频出现,后来也被用到了《生活大爆炸》中,是典型的理工男影视道具。
三维国际象棋或许难度太高,但如果只是稍微改改二维的国际象棋规则,会带来什么不一样的体验呢?
只是对于棋类游戏而言,规则非常重要,往往牵一发而动全身。如果改的不好,很可能会导致游戏变得不公平,或者无趣。但要确认新规则的有效性,特别是对于国际象棋这类探索空间非常大的游戏,需要大量的玩家玩大量的游戏后,才能确定新规则是否公平,新游戏是否有趣。
有没有更智能的方法呢?
当然有!这一次,DeepMind创始人Demis Hassabis联手国际象棋世界冠军Vladimir Kramnik,用AlphaZero玩出了新花样。他们尝试了多种不同的国际象棋变体,每一种变体都对经典国际象棋的规则做了些许改变,并用AlphaZero在新规则下进行自我对弈(self-play)。
Vladimir Kramnik是俄罗斯国际象棋特级大师,并且2000年至2007年间的国际象棋世界冠军。
2017 年底,DeepMind 发表了 AlphaZero的论文,AlphaZero是可以从零开始自学国际象棋、将棋和围棋的系统,并最终在这三个棋类游戏上都打败了世界最顶尖的程序。2018年底,DeepMind 对 AlphaZero 进行全面评估的论文发表在Science封面上。AlphaZero不需要任何内置的人类专业知识,只知道基本的游戏规则,并从随机游戏开始训练,就能实现世界最强。
所以,用AlphaZero来探索新规则下的国际象棋非常合适。

论文地址:arxiv/pdf/2009.04374.pdf
1 9种新型国际象棋
设计一套足够吸引人、而且公平的游戏规则并非易事。现代国际象棋已经发展了几个世纪,如果没有相关经验,盲目修改游戏规则对整个棋局的影响是很难预测的。AlphaZero提供了一种替代性的计算手段来评估棋局的公平性。它可以不断从自身获得的经验中学习,不需要任何人类监督,就能对任何规则改动进行评估进而得到近乎最优的策略。
在本研究中,作者使用AlphaZero来创造性地探索和设计新的国际象棋规则。目前人们对费舍尔随机棋(Fischer Random Chess)越来越感兴趣,因为其涵盖了经典国际象棋的大量开局理论、职业比赛中高比例的平局的特点,此外还需要双方棋手在开战前进行大量的练习。
作者比较了另外9种国际象棋的变体棋种,这些规则的变化可以激发出很多新的战略和战术模式,同时还能使对局接近于原来的水平。通过使用AlphaZero学习每个棋种变体的最佳策略,我们就可以清楚,如果采用这些变体,人类高手之间的对局会是什么样子。
从定性上看,这些棋种变体具有动态的特点。分析表明,相同棋子在不同棋种变体中的重要性不同,一些棋种变体比经典的国际象棋在整体棋局中表现出了更强的决胜性。该发现证明了现代国际象棋有更多规则变化的可能性。
2 规则一直是活的
流行的游戏往往会随着时间的推移而不断发展,现代国际象棋也不例外。最初的国际象棋游戏起源于6世纪的印度,然后传到波斯和穆斯林世界,后来传到欧洲和全球。
在中世纪,欧洲国际象棋主要还是以沙特兰兹为基础,这是一种起源于萨珊帝国的早期变体,是以印度的Chaturanga为基础的,在这种变体中,皇后和主教的走法受到更多限制,棋子的威力也不如现代国际象棋,城堡当时还不存在。
除了将军以外,还可以通过暴露对方的国王来取胜,即吃掉对方所有其他棋子。在沙特兰兹中,僵局被认为是胜利,而现在则被认为是平局。
几个世纪以来国际象棋的演变可以看作是搜索空间复杂性的变化和游戏最终结果的不确定性变化,现代规则比较重视后者,认为这是国际象棋游戏体验的重要因素。
人们对国际象棋进一步发展的兴趣并没有消退,特别是近来职业比赛中决定性的对局越来越少,选手们对于经典象棋的理论越来越依赖,再加上人们对象棋千变万化的玩法的好奇心和不断探索的欲望,产生了许多国际象棋的变体。
这些变体涉及对棋盘、棋子位置或整体规则的改变,为棋手提供了"一些在普通国际象棋中无法体会到的微妙的有趣的东西"。目前最著名和最流行的国际象棋变体可能是Chess960或费舍尔随机棋,其中第一横排的棋子是从960种随机排列中选取的,这使得前期的理论准备变得不可行。
国际象棋和人工智能有着千丝万缕的联系。图灵(1953年)提出:"能不能制造一台机器来下棋,并逐渐改进它的下法,人们再从它的经验中获取技巧?"
虽然计算机国际象棋自20世纪50年代以来稳步发展,但图灵问题的第二部分直到最近才完全实现,即AlphaZero的诞生。它的出现又催生了新的项目,如Leela Chess Zero和对现有国际象棋引擎的改进。
CrazyAra采用了相关的方法来对Crazyhouse(也是一种国际象棋变体)进行了实验,不过它需要从现有的人类游戏数据进行预训练。原始AlphaZero系统的一些特性被证明可以泛化到Atari等领域,即使在没有精确环境模拟器的情况下也能保持其在国际象棋上的性能。AlphaZero还显示出超越游戏环境的能力,最近有研究表明可以将该模型应用在量子动力学的全局优化中。
在任何游戏上训练AlphaZero时,并不需要事先的游戏知识。因此,我们可以快速探索不同的规则集,并通过定量和定性的比较来确定所产生的游戏风格。
这篇文章中,作者以AlphaZero的视角来研究国际象棋规则的几种假设性变体,进而推测出国际象棋界可能感兴趣的棋种变体。作者用AlphaZero研究了被Vladimir Kramnik公开倡导的No-castling变体,其出现在了2019年12月19日的职业比赛中。
当时Luke McShane和Gawain Jones在伦敦国际象棋精英赛期间进行了有史以来第一场特级大师的No-castling比赛。此后,2020年1月在印度金奈举办了第一届No-castling国际象棋比赛,出现了89%的决胜局。
3 规则变更示例
更改国际象棋的规则有多种方式,在这项工作中,作者限于考虑原子级变化,以使游戏尽可能接近经典的国际象棋。
在某些情况下,需要对50步规则进行更改,以避免出现游戏无法结束的情况。这是为了保留原始游戏的对称性和美学吸引力,同时希望通过新的开局、中局或尾局模式以及新颖的开局理论来发现动态的变体。
考虑到这一点,作者没有考虑任何涉及棋盘本身、棋子数或棋子布局的更改。表1列出了作者研究的规则变更。目前还没有进行严格的审查,将僵局视为胜利在国际象棋界是一个悬而未决的问题。
表1中列出的每个规则更改都可能以期望或不期望的方式影响游戏。例如,考虑No-castling变体(不允许使用城堡)。不使用城堡的一个可能结果是,如果国王在比赛中暴露更多,并且需要时间来确保国王的安全,那将导致游戏风格更倾向于进攻。
然而,由于防御方也有反击的机会,因此无法轻易保护自己的国王可能使攻击成为糟糕的选择。在经典象棋中,玩家通常在发动攻击之前先进行防御。因此,这种改变可能导致比赛变得无趣,以及游戏方式变得更加受限。
按照传统,评估规则的唯一方法是让大量的人类玩家长时间玩游戏,直到积累了足够的经验和理解为止。这不仅是一个漫长的过程,而且还需要大量玩家的支持。借助AlphaZero,可以自动化这一过程,并在一天内模拟相当于几十年的人类游戏,从而使我们能够通过计算机测试这些假设,并观察游戏中每个已考虑变化的新兴模式和理论。

表1:对国际象棋规则进行的9种更改的列表。
图1用示例布局对每个变体进行了展示,涉及变体中出现的新战略和战术主题。

图1:(a)No-castling中的一个例子:图中展示了两个国王都没有立即获得安全,并且仍处于游戏中场的典型布局。

图1:(b)No-castling(10)的一个例子:比赛趋向于进展较慢且更具策略性,以便以后开始出动城堡。在第11步中,首先是黑城堡出动,紧接着是白城堡出动。

图1:(c)Pawn-one-square的一个例子:黑方刚将骑士移至a5。在经典象棋中,这可能违反直觉,因为有可能将卒子打到b4,对骑士捉双。但是,这里的卒子不能一口气移动到那个格子,所以黑方的走法是合理的。
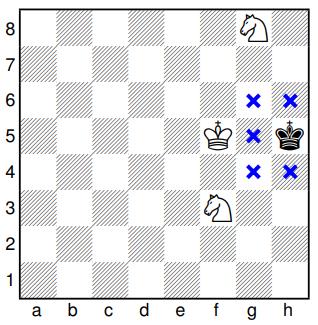
图1:(d)Stalemate = win的一个示例:原来在经典象棋中平局的布局,现在改为获胜。

图1:(e)Torpedo的一个例子:白方需要快速反击,并使用torpedo移动:b4-b6来实现。黑方以Rh1做出回应,白方以另一个torpedo移动b6-b8 = Q越过皇后。

图1:(f)Semi-torpedo的一个示例:将卒子从第3/6横排快速前进的能力使黑方做出了这样的选择:d6-d4,从而形成强制战术。

图1:(g)Pawn-back的一个例子:在这里,黑方利用新规则来吃白方的中央卒子(e5),同时通过卒子后移d5-d6,为b7主教打开对角线。

图1:(h)Pawn-sideways的一个例子:在牺牲了f2的骑士之后,黑方将卒子进行横向移动f7-e7,用于战术目的,对白方国王打开直线做准备,同时攻击d6上的骑士。

图1:(i)Self-capture的一个例子:白方城堡通过Rxh4吃掉自己的卒子,对黑方国王产生威胁。
4 定量评估图2展示了AlphaZero在不同时间控制条件下的自我对弈。由于在相同条件下以确定性方式确定走棋,因此通过对每场比赛的前20步进行与MCTS访问次数成正比的采样来实现多样性。
在所有变体中,平局的百分比随着思考时间的延长而增加。这似乎表明,从理论上讲,这些象棋变体中可能会先确定起始位置,就像经典象棋一样,而且某些变体更难玩,涉及更多的计算和更丰富的模式。
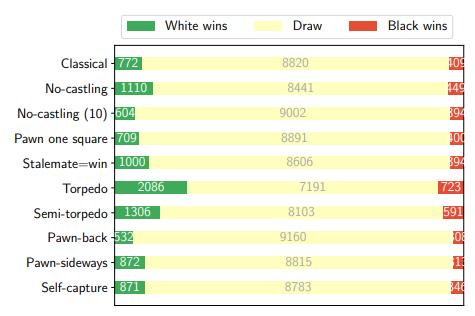
图2:(a)以每步1秒的速度,对每种国际象棋变体用AlphaZero自我对弈10,000局的结果。

图2:(b)以每步1分钟的速度,对每种国际象棋变体用AlphaZero自我对弈1000局的结果。
表2展示了白方在不同对局条件下的经验性得分,即对于每个国际象棋变体:模型训练结束时的自我对弈、每步1秒对局和每步1分钟对局的得分。每步1秒对局和每步1分钟对局的多样性是通过对每盘棋的前20个出棋按其MCTS访问次数比例进行抽样来实现的。
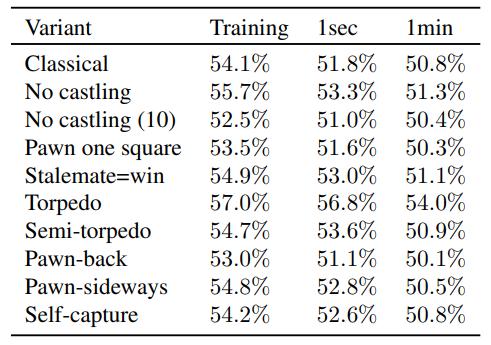
表2
图3展示了平局率的对比。在两种时间控制下,最具决胜性的变体是Torpedo、Semi-torpedo、No-castling和Stalemate=win,这四种变体也使白方拥有最大的先手优势。

图3:(a)每步1秒对局的和棋率对比,对每个变体使用AlphaZero自我对弈10,000局。

图3:(b)每步1分钟对局的和棋率对比,对每个变体使用AlphaZero自我对弈1000局。

图3:(c)每步1秒对局预期得分的对比,对每个变体使用AlphaZero自我对弈10,000局。

图3:(d)每步1分钟对局的预期得分的对比,对每个变体使用AlphaZero自我对弈1000局。
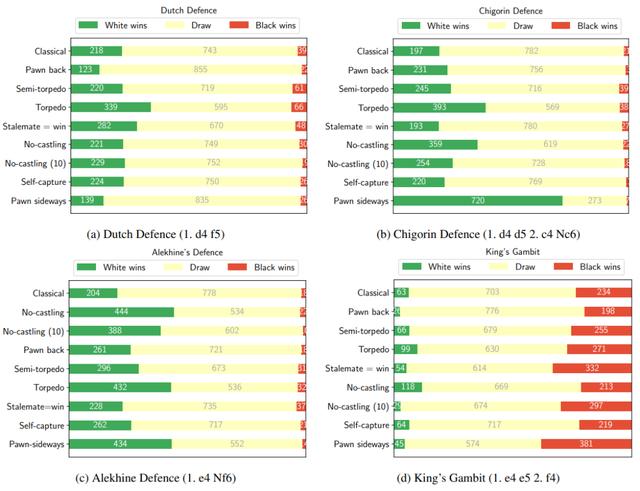
图4表明,相同的开局位置可以根据所考虑的变体提供不同程度的优势。图中展示了AlphaZero作为白方,进行1000局,每步大约耗时1秒,赢、输、平局的次数,同时始终保持最佳走棋。
结果中的随机性源于搜索过程中MCTS线程的异步执行。因此,这些结果表明,对于以下每种开局,“主线”延续(“main line” continuation)是多么有利:荷兰防御(Dutch Defence)、奇戈林防御(Chigorin Defence)、阿廖欣防御(Alekhine Defence)和王翼弃兵(King’s Gambit)。
为了评估本研究中所考虑的国际象棋变体之间的玩法差异,采取了将变体的定量评估与代表性对局的专家分析相结合的方法。虽然开局的多样性增加了国际象棋变化的吸引力,但走法模式的类型等主观问题不可能完全定量地捕捉到。
因此,为了对吸引力进行定性评估,作者借鉴了Vladimir Kramnik这位象棋特级大师的经验。
另外,通过描述典型的模式,希望为棋手提供洞察力,帮助他们判断这些国际象棋变体的有趣之处。在分析中,使用了前面提到的1,000个1分钟/步的对局以及200个1分钟/步的对局,这些游戏区别在于早期开局。
通过观察1,000个1分钟/步的对局,能够评估AlphaZero在每个国际象棋变体中首选的打法风格。而通过200个1分钟/步的对局,能够观察到不同开场处理方式的变化模式,以及在每个规则变化下,哪些开场方式更有希望赢得比赛。
以下是Kramnik对每个变体进行定性分析的主要总结:
No-castling是一种令人兴奋的变体,因为国王的安全往往会影响到双方的安全,允许同时进行攻击和反击,而且当达到平等时,往往是动态的,而不是 "干(dry) "的。摆放国王的多种方法及其时机,给开局的下法增加了复杂性。
Pawn one square的变体可能会吸引那些喜欢慢速战略游戏的玩家,因为在设置卒子的时候有可能进行换位。卒子的机动性降低,使其更难发动快速攻击,使游戏整体上不那么具有决胜性。
Stalemate=win对开局和中局的影响不大,主要是影响某些终局的评价。因此对棋局来说,它并没有增加局的决胜性,因为可以不依靠残局作为平局而进行防御。因此,这种棋型变化对于绕开已知理论或使棋局在高水平上大幅度提高决胜性的作用不大。
Torpedo和Semi-torpedo都会让棋局变得更有活力,更有决胜性,特别是Torpedo会导致棋局各阶段出现变化。另外,由于过路吃兵很难被阻止,所以它们变得非常重要。
Pawn-back可以恢复对弱化格子的控制,并消除一些格子弱点。它还引入了打开对角线和格子占用的其他可能性。与直觉相反,尽管通常将棋子向后移动是一种防御性的动作,但鉴于可以将棋子更早地推进,这可以提供更具侵略性的选择,因为始终可以选择将棋子向后移动以覆盖弱化的格子 。AlphaZero非常喜欢与对方进行法国防守,这特别有趣。
Pawn-sideways非常复杂,即使那些习惯于经典国际象棋的棋手,对此模式有时也是非常 "陌生 "。卒子的结构多变,不可能创造出永久性的卒子弱点。因此,这种棋型变体要求我们重新思考如何处理任何给定的局面,处理方式会变得非常具体,并且会依靠深入的计算。另外,重组布阵需要时间,棋手需要利用这些时间来创造出其他类型的优势。AlphaZero在这个变体中的许多对局都是相当有战术性的,有些还涉及到在经典规则下无法实现的新颖战术。
Self-capture相当有趣,因为它会选择牺牲自己的棋子。Self-capture可以出现在对局的各个阶段,但并非每一盘棋都涉及。但它们确实在相当大比例的对局中出现,而且在一些对局中它们会出现更多。例如,Self-capture招数可以用来在进攻中为棋子开档和格子;通过牺牲卒链中的一个卒来打开封等等。
6 总结
整个论文的工作集中于:训练了AlphaZero模型来评估国际象棋的棋局。在这些规则变化下训练AlphaZero模型可以帮助我们在几个小时内有效地模拟“几十年”人类游戏,并能回答问题:在国际象棋变体中,既定理论情况下(developed theory),这盘棋可能会是什么样子?此外,类似的方法可以用于其他类型游戏中的自动平衡游戏机制。
为了评估规则变化的后果,作者结合训练模型和自我对弈的定量分析,进行了深入的定性分析,在分析中发现了,许多经典国际象棋规则不可能出现的新模式和想法。这表明,在本研究考虑的棋谱中,有几个棋谱变体甚至比经典棋谱更具决胜性:Torpedo、Semi-torpedo、No-castling和Stalemate=win。
另外,还量化了多种开局玩法,因为决胜性变体可能需要更精确的下法,每步棋的可信选择更少,所以,整体开局多样性和决胜性之间存在负相关。对于每一种国际象棋变体,作者还根据10000场AlphaZero对局的结果估计了每一个棋子的“物质价值”,以便使人类棋手更容易理解游戏。
[赠书福利]
在AI科技评论今天推文第三条“《柏拉图与技术呆子》:探讨人类与技术的创造性伙伴关系”留言区留言,谈一谈你对本书的相关看法、期待等。
AI 科技评论将会在留言区选出5名读者,每人送出《柏拉图与技术呆子》一本。
活动规则:
1. 在留言区留言,留言点赞最高且留言质量较高的前 5 位读者将获得赠书。获得赠书的读者请联系 AI 科技评论客服(aitechreview)。
2. 留言内容和留言质量会有筛选,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2020年9月11日 - 2020年9月18日(23:00),活动推送内仅允许中奖一次。
点
,直达图书购买链接
,