提到大数据的特征,大家都会联想到大数据的4V特征,即Volume(大容量),Variety(多样式),Velocity(高速性),Value(价值性)。

图 1‑2大数据的4V特征
结合我国大数据的研究,《大数据领导干部读本》这本书曾概括了大数据的十字特征, “大杂多全快,久活密稀联”,来区别大数据与传统数据的特征。
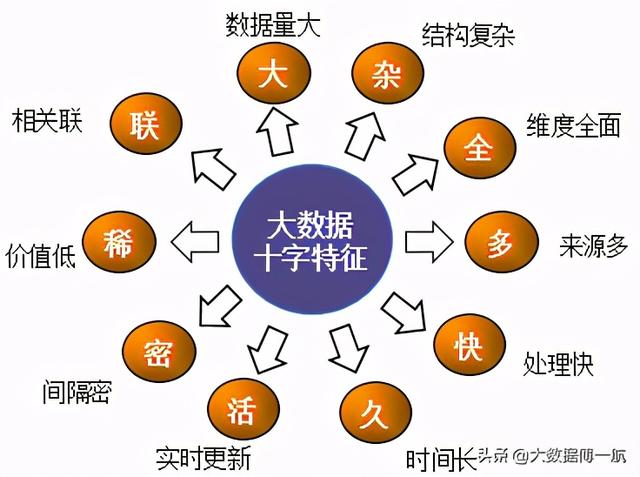
图 1‑3大数据的十字特征
大—数据量大
指的是数据规模大,即所说的海量数据。
2012年,Facebook宣布每天有25亿条内容,3亿上传照片数,500 TB新产生的数据量;2017年,微信每天9亿登陆,380亿条消息,61亿语音次数,2亿视频通话,10 亿图片。
据国际数据公司(IDC)估计,全球数据总量预计2020年达到44ZB,中国数据量将达到8060EB,占全球数据总量的18%。
杂—结构复杂
指的是数据的存储类型多种多样,数据结构复杂。
数据的形式也是多样化的,可以是连续的数值,也可以是文字、符号(数字数据),或者声音、图像等等。
传统的小数据,为了便于存储和快速处理,一般都是结构化的数据。而大数据,不仅包含了结构化的数据,更多的是非结构化和半结构化的数据,比如互联网上的文本、图片、音视频等等,都是大数据。
全—维度全面
指的是业务数据的多维性,即数据样本的维度较多,能够全面呈现数据对象。
比如要了解一个用户行为,不仅要收集其基本数据(比如性别、年龄、住址、联系方式),也还要收集其搜索浏览数据(比如百度搜索关键词、浏览网页地址),甚至交易数据(淘宝购物数据、京东购物数据)等等多个维度的数据,这样才能够全面体现用户的行为。
不过,全是一个相对的概念,绝对的全是没有的。
多—来源多
指的是数据的来源多,不仅来源于销售,也来源于生产;不仅来源于企业内部,也包含很多外部数据。实际上,单个企业一般只会是基于某种业务目的来收集相应的数据。比如,销售数据只会保存在交易数据库中,而用户的浏览数据则会来源于网站日志,这样数据的来源就比较多样化了。
快—处理速度快
这里的快有两层意思:一是指数据产生的速度快,二是要求数据处理速度也要快。
按照新的摩尔定律,每两年产生的数据量相当于以前全部数据量的总和,这么快的增长速度,也就要求数据的处理效率要高,否则,其数据的意义就不大了。
比如,在交通路口拍摄的照片需要及时传回到大数据系统中,进行及时处理,从照片中提取出经过某个路口的车牌号、时间点等信息,这样才以便于公安或交警部门快速地捕获指定的违章车辆,快速进行拦截。如果处理的速度不够快,或者数据分析后的结果就意义已经不大了。
久—时间跨度长
指的是大数据的时间范围要足够长。时间越长,就越能发现事物的长期规律。
就比如全球的经济危机,其爆发的周期约为10年,差不多每隔十年左右才会发生一次。如果收集的数据时间跨度太短,是不太可能从数据中发现这样的周期性规律的。
活—实时处线
指的是数据的实时性,要求数据是实时在线的,能够随时查看和计算的。
就比如交通行业要求的大数据,要能够实时在线处理,以呈现实时路况,才能有效地利用大数据及时发现拥堵,并指导车辆分流,规避拥堵。
密—数据密度
指的是收集数据的时间间隔,或者地域间隔要足够地短,这样才能准确地用来描述业务的情况。
比如,公交车上的GPS数据,其两次上报的时间间隔要足够地短,其位置间隔也要足够地短,这样才能用于精确定位,这样的数据才有实用价值。
稀—价值低
指的大数据的价值密度低,即有价值数据的比例比较小。
特别是一些监控视频数据,其中真正有价值的数据也许只有1~2秒。但是,为了得到这几秒的有价值的信息,我们却必须保存大量的视频数据。正如有人自我揶揄说,为了提炼一点点金子,我们得保存整个沙滩。
联—关联性
指的是数据之间的相关性。万物皆有联,万事万物都是有某种联系的,体现在数据上就是数据与数据间的相关性,可以探索业务各种因素之间的相互影响关系。
正如舍恩伯格所说,大数据关注相关关系更胜于因果关系。
这十个字,分别从数据的特征、数据的采集、数据的处理以及数据分析等不同的角度来描述大数据,是比较全面的。






