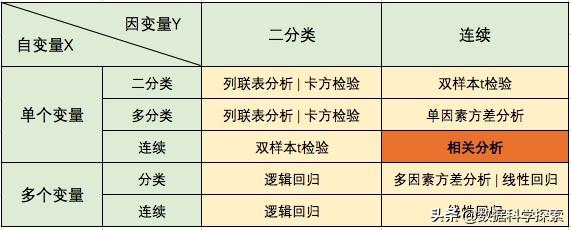
变量类型与推荐的假设检验方法
可以看到,当我们探索两个连续变量之间的关系时,相关分析是一个很好的选择。那么,相关分析的原理是什么?如何在Python中实现相关分析呢?
一、Pearson相关系数
针对两个独立的服从正态分布的连续变量,我们常用Pearson相关系数来衡量它们之间的相关性。Pearson相关系数的值域为[-1, 1],当相关系数小于0时,表明两变量之间存在线性负相关关系;当相关系数大于0时,表明两变量之间存在线性正相关关系;当相关系数等于0时,表明两变量之间无明显的相关关系。
当变量不符合正态分布或者是顺序型变量时,我们常用Spearman相关系数来衡量变量间的关系;当我们需要探索变量间的非线性关系时,可以使用Kendall相关系数。不过这些不在本篇的讨论范围内,如果感兴趣的人多,可以在下方留言。
一般情况下,我们用r来表示相关系数,r的取值与相关程度之间的关系如下:

皮尔逊相关系数的计算很简单。假设我们有两组数据,一组为x,一组为y。那么x与y之间的协方差作为分子,x的标准差与y的标准差之间的乘积作为分母,得到的就是x与y之间的相关系数r,我们用公式表示如下:

计算出相关系数r之后,我们还要检验它是否具有统计学意义,即我们常说的是否显著。这里我们检验的计算公式为:

然后我们从t分布中找到对应的P值,与我们设定的显著性水平做一下对比,比如说我们设定了显著性水平为0.05,当P值小于0.05时,我们就拒绝零假设,认定x与y之间存在显著的线性相关。需要注意的是,P值大小不代表两个变量间相关性的强弱,r的大小才是衡量相关性的统计量。
当然,现在这些繁琐的过程我们可以统统交给计算机来处理。
二、Python相关分析
在pandas中,计算相关系数非常简单:

我们还可以用热力图来更直观地感受一下:
sns.heatmap(iris.corr(), cmap='bwr', center=0)

除了sepal_width变量与其他变量负相关以外,其他三个变量间都高度正相关。
但是我们注意到,这里并没有显著性检验的信息,那么我们如何得到这些信息呢?答案就是使用Scipy,Scipy是Python中一个非常强大的科学计算库,提供了很多关于统计、科学计算的方法。
scipy.stats.pearsonr方法会根据输入的两组数据,计算Pearson相关性,返回相关系数r以及显著性检验的P值,当P值低于我们设定的显著性水平时,即可认为变量间显著相关。
from scipy.stats import pearsonr pearsonr(iris.sepal_length, iris.petal_length)
输出为:
(0.8717537758865832, 1.0386674194497583e-47)

好了,关于Pearson相关的分享就到这里,有任何问题可以在下方留言,我会及时回答。另外,除了计算相关系数,散点图、回归图等都很适合用来探索变量间的关系,感兴趣的可以去看我的历史文章中关于数据可视化的几个系列。
,