之前发布过,但重要的图片没有显示出来,所以重新发布一次。
正文来了:
最近帮老同学处理一个差不多200页的pdf文件提取文字的处理,经过一番处理后发现都存在一些自己不满意的地方。
老同学有完成时间的要求,所以选择了一个相对安全的操作:【pdf文件按页转换为图片格式】- 【再利用WX的文字提取功能】-【逐个图片提取文字后复制粘贴到一个txt或doc文件中】 。因为需要截图 - 传图到手机 - 微信文字提出 - 复制文字 - 发回电脑端 -粘贴到文件,整个操作流程重复、费劲,伤眼、伤腰、伤精力....最终花了半个工作日才搞掂,后续的格式问题交回老同学再二次加工了。
此后产生了一个想法:利用python的技术进行自动处理。思路:PDF文件按页批量转换生成图片格式,每个图片通过OCR实现文字提取,所有提取的文字写入一个txt文件里面。全称自动化,无需手工切入,想想都觉得好有满足感。于是网上查阅了资料,也花费了一些闲余时间,终于大功告成!
先来看看PDF原文件和运行代码后的文字提取结果,来个直观对比吧

PDF原文件

文字提取后输出到txt文件里面
下面是python两个重要过程的代码截图,分别是pdf文件按页切割为png图片,另一个是OCR识别文字提取
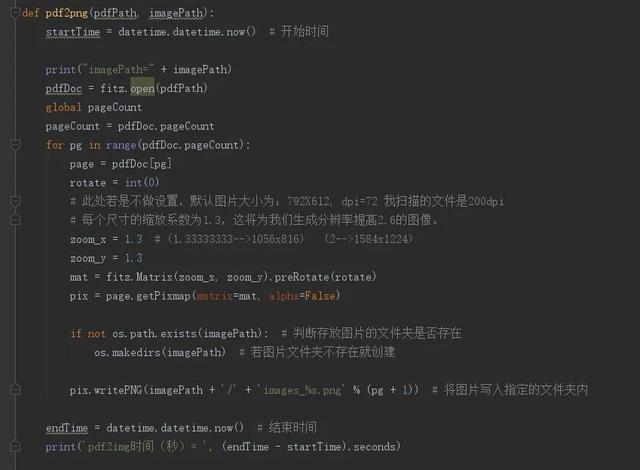
PDF按页转换生成图片文件
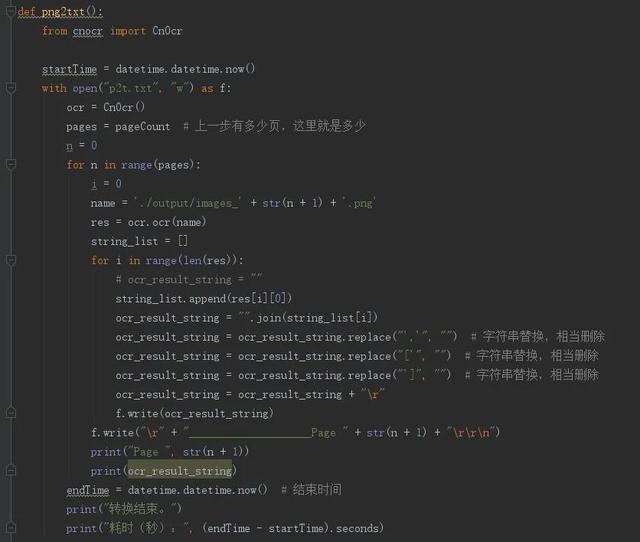
OCR文字提取
本案例四页PDF的文字提取速度非常快,从代码捕获的时间显示用时全程大概10秒。无论效率和文字提取都比较满意,但也存在不足,遇到PDF里面有图片的识别不出来的。
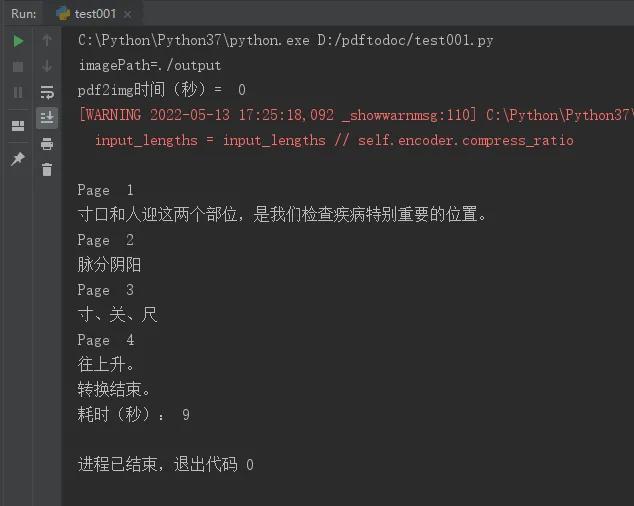
四页PDF转换大概用时10秒
本次分享到此结束,希望大家有所收获吧!
,




