什么是ResNet,本项目给大家介绍残差网络ResNet。
ResNet是一种残差网络,咱们可以先简单看一下ResNet的结构,再对它的结构进行详细介绍。

从图可以看出,残差网络是由多个结构类似的块堆叠起来的,这样的块是残差网络的基本单元(称为残差块),ResNet是由多个这样的残差块堆叠起来的。残差块长这样:
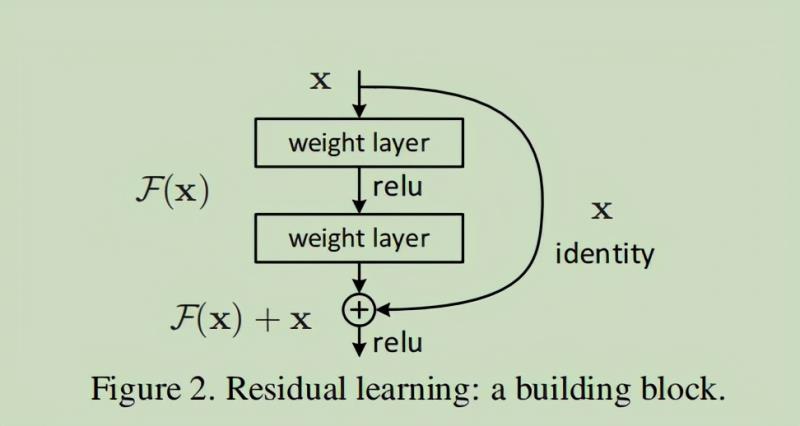
那么可能会有小伙伴疑问,干嘛非要用残差块来构建这么一个深层网络呢?干嘛不直接用卷积层对网络进行一个堆叠呢?
为什么要引入ResNet?
我们知道,网络越深,咱们能获取的信息越多,而且特征也越丰富。但是根据实验表明,随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。这是由于网络的加深会造成梯度爆炸和梯度消失的问题。
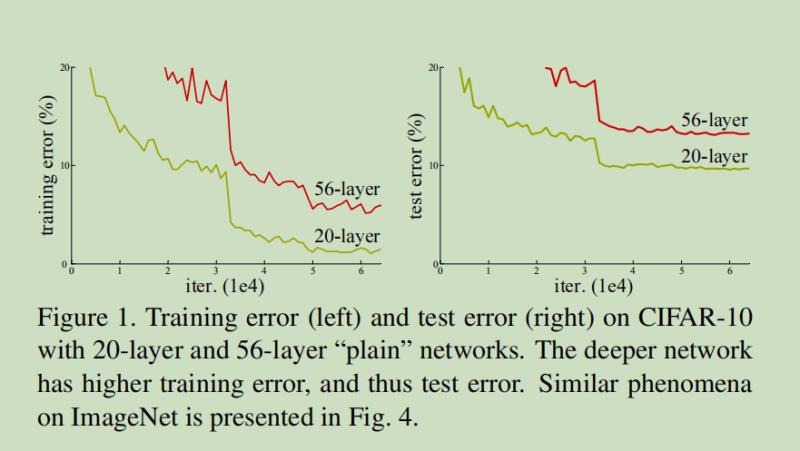
网络加深时测试错误率和训练错误率显示目前针对这种现象已经有了解决的方法:对输入数据和中间层的数据进行归一化操作,这种方法可以保证网络在反向传播中采用随机梯度下降(SGD),从而让网络达到收敛。但是,这个方法仅对几十层的网络有用,当网络再往深处走的时候,这种方法就无用武之地了。
为了让更深的网络也能训练出好的效果,何凯明大神提出了一个新的网络结构——ResNet。这个网络结构的想法主要源于VLAD(残差的想法来源)和Highway Network(跳跃连接的想法来源)。
ResNet详细解说
再放一遍ResNet结构图。要知道咱们要介绍的核心就是这个图啦!(ResNet block有两种,一种两层结构,一种三层结构)两种ResNet block(代码给出了两种残差块以供选择)咱们要求解的映射为:H(x)现在咱们将这个问题转换为求解网络的残差映射函数,也就是F(x),其中F(x) = H(x)-x。
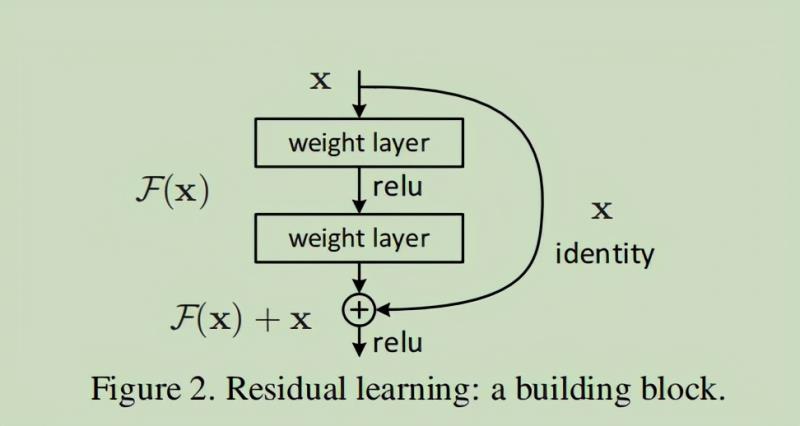
残差:观测值与输入值之间的差。这里H(x)就是观测值,x就是输入值(也就是上一层ResNet输出的特征映射)。我们一般称x为identity Function,它是一个跳跃连接;称F(x)为残差映射ResNet Function。
那么咱们要求解的问题变成了H(x) = F(x)+x。
有小伙伴可能会疑惑,咱们干嘛非要经过F(x)之后再求解H(x)啊?X的跳跃连接有什么好处吗?因为如果是采用一般的卷积神经网络的化,原先咱们要求解的是H(x) = F(x)这个值对不?ResNet相当于将学习目标改变了,不再是学习一个完整的输出H(x),只是输出和输入的差别H(x)-x,即残差。学习一个微小的波动F(x)不比学习一个整个x更容易吗?X的跳跃连接除了让网络的学习有了基础,在梯度反向传播时也能更直接的传到前面的层去。残差块残差块通过跳跃连接shortcut connection实现,通过shortcut将这个block的输入和输出进行一个逐点element-wise的加叠,这个简单的加法并不会给网络增加额外的参数和计算量,同时却可以大大增加模型的训练速度、提高训练效果,并且当模型的层数加深时,这个简单的结构能够很好的解决退化问题。注意:如果残差映射(F(x))的结果的维度与跳跃连接(x)的维度不同,那咱们是没有办法对它们两个进行相加操作的,必须对x进行升维操作,让他俩的维度相同时才能计算。升维的方法有两种:1、用0填充;2、采用1*1的卷积。一般都是采用1*1的卷积。
#以下是代码:#导入库mport torchimport torch.nn as nnimport torch.nn.functional as Ffrom torch.autograd import Variable#定义残差块(BasicBlock是小残差块,Bottleneck是大残差块)class BasicBlock(nn.Module):#定义block expansion = 1 def __init__(self, in_channels, channels, stride=1, downsample=None):#输入通道,输出通道,stride,下采样 super(BasicBlock, self).__init__() self.conv1 = conv3x3(in_channels, channels, stride) self.bn1 = nn.BatchNorm2d(channels) self.relu = F.relu(inplace=True) self.conv2 = conv3x3(channels, channels) self.bn2 = nn.BatchNorm2d(channels) self.downsample = downsample self.stride = stride def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) if self.downsample is not None: residual = self.downsample(x) out += residual out = self.relu(out) return out#block输出class Bottleneck(nn.Module): expansion = 4 def __init__(self, in_planes, planes, stride=1): super(Bottleneck, self).__init__() self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d(planes, self.expansion*planes, kernel_size=1, bias=False) self.bn3 = nn.BatchNorm2d(self.expansion*planes) self.shortcut = nn.Sequential() if stride != 1 or in_planes != self.expansion*planes: self.shortcut = nn.Sequential( nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(self.expansion*planes) ) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = F.relu(self.bn2(self.conv2(out))) out = self.bn3(self.conv3(out)) out += self.shortcut(x) out = F.relu(out) return out#定义残差网络class ResNet(nn.Module): def __init__(self, block, num_blocks, num_classes=9,embedding_size=256): super(ResNet, self).__init__() self.in_planes = 64 self.conv1 = nn.Conv2d(1, 64, kernel_size=3, stride=1, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(64) self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1) self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2) self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2) self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2) self.avg_pool = nn.AdaptiveAvgPool2d([4, 1]) self.fc=nn.Linear(512*4, embedding_size) self.linear = nn.Linear(embedding_size, num_classes) def _make_layer(self, block, planes, num_blocks, stride): strides = [stride] + [1]*(num_blocks-1) layers = [] for stride in strides: layers.append(block(self.in_planes, planes, stride)) self.in_planes = planes * block.expansion return nn.Sequential(*layers) def forward(self, x): x = torch.tensor(x, dtype=torch.float32) out = F.relu(self.bn1(self.conv1(x))) out = self.layer1(out) out = self.layer2(out) out = self.layer3(out) out = self.layer4(out) out =self.avg_pool(out) out = out.view(out.size(0), -1) embedding=self.fc(out) out = self.linear(embedding) return out,embedding#从18层的到101层的,可以根据自己需要选择网络大小,大的网络选用了大的残差块,#第一个参数指明用哪个残差块,第二个参数是一个列表,指明残差块的数量。def ResNet18(): return ResNet(BasicBlock, [2,2,2,2])def ResNet34(): return ResNet(BasicBlock, [3,4,6,3])def ResNet50(): return ResNet(Bottleneck, [3,4,6,3])def ResNet101(): return ResNet(Bottleneck, [3,4,23,3])def ResNet152(): return ResNet(Bottleneck, [3,8,36,3])总结:在使用了ResNet的结构后,可以发现层数不断加深导致的训练集上误差增大的现象被消除了,ResNet网络的训练误差会随着层数增加而逐渐减少,并且在测试集上的表现也会变好。原因在于,Resnet学习的是残差函数F(x) = H(x) – x, 这里如果F(x) = 0, 那么就是上面提到的恒等映射。事实上,resnet是“shortcut connections”的,在connections是在恒等映射下的特殊情况,学到的残差为0时,它没有引入额外的参数和计算复杂度,且不会降低精度。 在优化目标函数是逼近一个恒等映射 identity mapping, 而学习的残差不为0时, 那么学习找到对恒等映射的扰动会比重新学习一个映射函数要更容易。参考论文: Deep Residual Learning for Image Recognition
残差网络有两个版本,ResNet_v1和ResNet_v2,这两者有何区别,为啥大多用的是ResNet_v2,它有什么优良的性质呢,下一篇残差网络深度解析为您解答。





